A Westworld View of AI: 1973 vs. 2016
The original version of this article was published as “HBO’s Westworld artificial intelligence, then and now” and can be found on VentureBeat.
Similar to today’s sentiment, people were enthralled by artificial intelligence in 1973 — the year Michael Crichton released the film, Westworld. The film became MGM’s biggest box office hit of the year, yet launched the same year as the first AI winter, a massive fallout in AI resources, dashed expectations, and dwindling interest over the ensuing decades. Today, Westworld is back, and the immense changes in deep learning, open source, and computing power are fundamentally shifting AI’s future. Compute capacity and the technology’s capabilities have now advanced far enough that AI can complement and accelerate society, versus the trough of disillusionment realized in 1973.
HBO’s new version of Westworld, produced by Jonathan Nolan and Lisa Joy, is arguably one of the most popular shows on TV today. The futuristic, western themed show taps into our widespread AI obsession and its popularity is showing that consumers (not just entrepreneurs, corporates, and VCs) are fascinated by AI’s potential. Westworld’s release mirrors a robust AI ecosystem, where entrepreneurs, VCs, corporations and consumers are getting in on the action.
Looking back to 1973…
In 1973, the underlying goals of AI were similar: to automate tasks and bottlenecks across organizations, and eventually everyday life. Government, researchers and corporations drove AI’s progress, while consumers were infatuated (exampled by Westworld’s box office success) but did not have the channels to consume the technology or understand its applications and limitations. Consumer interest was not enough for AI to continue on the same trajectory of funding, and just months after Westworld’s release, James Lighthill released a pessimistic report on AI, sparking a seven year lull period. Lighthill highlighted the growing difference in hype vs. reality, leading to universities slashing grant funding, government and defense cutting their AI budgets, and jobs and resources shifting to other initiatives.
Why it’s different today
Today, Ray Kurzweil, Jen-Hsun Huang, Andrew Ng, Yann LeCun, Yoshua Bengio and others are making bold predictions on AI’s potential and corporations are moving fast to prepare for opportunities in image recognition, voice detection, and conversational intelligence. The current AI revolution stretches far beyond university and defense research into our everyday lives, and is driven by 6 different components, nonexistent or under-resourced in the 1970s: research, compute power, storage costs, open source resources, talent and investment capital.

1) Research: Blame it [on the Cats]
Although the underlying components of AI have been around for more than 50 years, many point to Andrew Ng’s 2012 work at Stanford as the kickstart to today’s AI obsession. Ng and his team made a breakthrough in unsupervised learning through neural networks, the underpins of deep learning (a series of algorithms which loosely resemble the brain). Ng, a visiting professor at Stanford (founding lead of Google Brain team, now lead of Baidu’s 1,200 person AI team) decided to test unsupervised learning, or training data without a model, through a neural network. Andrew and his team used Youtube as the data set and collected some of the smartest AI researchers plus 16,000 computers to see if his deep learning model would recognize faces. It would, recognizing cat faces, and became known as the “cat experiment”. This test was only possible from the improvements in deep learning algorithms, due to decades of AI research.
Before 2012, traditional machine learning meant applying algorithms to reach an end variable — Ng’s test showed that deep learning (and building models for neural networks) had enormous potential. It is the expertise in designing the model that is still limited today.
In 1973, there was limited public research on AI, computing, deep learning, and how to run data on complex algorithms (NLP was just being created and Turing complete was announced only years before). Researchers of the 1970s misjudged AI’s progress, a miscalculation highlighted by James Lighthill 1973 report.
2) Compute Power driven by GPUs
Deep learning, running data through neural networks requires massive computational power, non-existent at the time of Crichton’s Westworld. Even before beginning the deep learning process, data sets need to be collected, synthesized, uploaded, and ingested into large databases and distributed computing systems.
Researchers and AI enthusiasts today can use Graphical Processing Units (GPUs) to train and learn from datasets. Neural networks must train on GPU chips for 400 hours leveraging decades of research in algorithms. Deep learning requires large datasets, need highly scalable performance, high memory bandwidth, low power consumption and great short arithmetic performance. Frameworks like Hadoop and Spark offer affordable databases, while Nvidia has a 20-year head start in GPU chip making, made for complex algorithms and computations. Nvidia chips, which include GPUs, are included in a majority of the intelligent hardware of today: autonomous vehicles, drones and have driven deep learning to new applications.
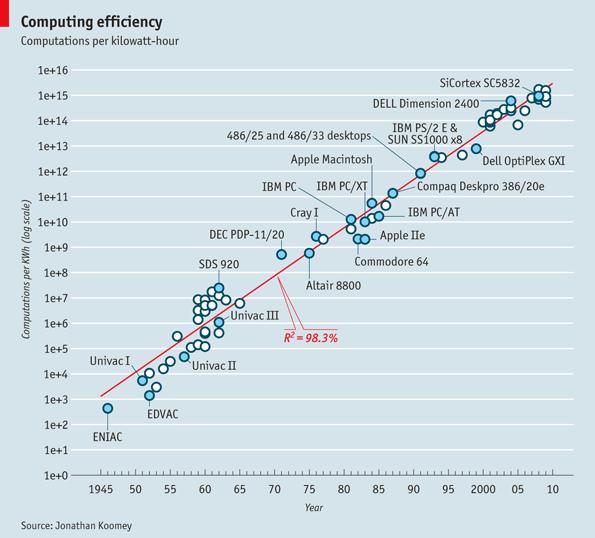
In 1973, compute power today was logarithmically weaker than compute power today (represented by Jonathan Koomey’s image).
3) Amount of Data↑& Cost of Storage↓
Today, we produce an insane amount of data which can be fed into deep learning models and produce more accurate outcomes in image recognition, speech recognition and natural language processing. Data is coming from devices like fitness trackers, Apple watches, enterprise IoT — and this data overload phenomenon is exponentially higher at the enterprise level. The coinciding rise of big data from mobile, the Internet, and IoT is creating mountains of data, prime for AI.
With all of the cloud services of today, large organizations can store and access data without breaking the bank. The rise of Box and Dropbox, combined with offerings from Google, Amazon and Microsoft have subsidized the cost of storage for big data.

In 1973, there was not a comparison in the amount of data — consumer watches were not streaming sleep cycles, health data, or any of our beloved add-ons today. In the enterprise, storage was all on-site (see 1970 computer room); if you didn’t have budget for servers and upkeep, you couldn’t participate.
4) Collaboration; Open Source Resources
Organizations in today’s hyper competitive market are pushing open source resources to attract AI talent, where IBM Watson has taken an early lead and competitors are racing to offer their own services. Google offers AI infrastructure via Google TensorFlow, and Microsoft offers CNTK, a framework for deep learning. Universities have open sourced their research where Berkeley released deep learning framework, Caffe and University of Montreal offers Python library, Theano.
While many are collaborating and open sourcing AI research to attract talent, some organizations are preparing for AI’s hypothetical “bad” side, in case a single party (or AI) surges ahead of the pack. Some of the players in this area include OpenAI, AI libraries like Open Academic Society, and Semantic Scholar. At the Neural Information Processing Systems conference in December, Apple announced they would open source AI, allowing researchers to publish their scientific papers.
In 1973, there was limited open source collaboration during the first Westworld era because progress was mainly happening in government and defense. Organizations shared coding languages, like LISP and researchers compared notes in person, but the Internet’s distribution piping was not available, hindering collaboration and AI’s progress.
5) AI Talent is ♚
Students are riding the AI wave by taking data science, NLP classes and universities and online courses have stepped up resources to meet demand. The pool has grown even larger through scholarship programs that provide funding to research and increasing the student number for computer science, math, and engineering streams which feed all levels of AI R&D.
In 1973, scholarships were rare and European universities cut AI programs after hype and reality became more distant, underscored by James Lighthill’s “Artificial Intelligence: A General Survey”.
6) Investment Frenzy
AI investment is increasing at an insane rate, growing 42% CAGR since 2011, according to Venture Scanner. VCs and tech giants are glued on AI’s potential, and are putting resources in people, companies, and initiatives. There have been a number of early exits in the space, many of which are glorified acqui-hires to build or enhance corporate AI teams.
In 1973, investment came primarily from defense, and government organizations like DARPA. As hype began to fade, DARPA made massive cuts to its AI budget and dollars to top researchers dwindled. At the time, venture capital was in its early days and VCs were more interested in semiconductor companies in the Bay Area than in AI.
________
AI is already in our daily lives (Prisma, Siri, Alexa) and will disseminate throughout the enterprise stack, touching every piece of the enterprise: devops, security, sales, marketing, customer support, and more. The six components listed above will make an even stronger case for AI, and its wave has similar potential to the Internet wave of the 90s, and mobile wave of the 2000s. This movement is already being realized within image and video recognition, to speech recognition and translation.
To prepare, organizations must understand the technology’s applications, limitations, and future potential. Companies like Facebook are treating AI more as a philosophy than a technology and Facebook CTO Mike Schroepfer outlined Facebook’s views at November’s Web Summit.
Deep learning’s influence has created the age of AI and entrepreneurs are in the Wild West of data acquisition, and training. Get your lasso, or get ready to be left behind.
Until next time,
Ash